

MD5以及例题

Zz1f
MD5
引言
MD5(Message Digest Algorithm 5,信息摘要算法5)是一种广泛使用的哈希算法,它将任意长度的“字节串”映射为一个固定长度的大数,并且设计者寄希望于它无法逆向生成,也就是所谓的“雪崩效应”。MD5算法在信息安全领域具有重要地位,常用于数据完整性校验、密码存储等场景。然而,随着计算能力的提升和密码学研究的深入,MD5算法的安全性已经受到严重挑战。
MD5算法的工作原理
MD5算法的核心思想是将任意长度的输入数据通过一系列复杂的变换,最终生成一个128位的哈希值。这个过程可以分为以下四个主要步骤:![[MD5算法流程图.png]]
填充:MD5算法首先对输入数据进行填充,使其长度达到一个特定的长度,这是为了使原始数据的长度可以被512整除。填充的方法是在原始数据后面添加一个“1”,然后添加足够数量的“0”,最后添加一个64位的整数表示原始数据的长度。
初始化缓冲区:MD5算法使用了一个64位的缓冲区,分为四个16位部分,用来存储中间结果和最终结果。这四个部分被初始化为特定的常数。
处理分组:填充后的数据被划分为长度为512位的分组,每个分组又划分为16个32位的子分组。然后,通过一系列的位操作和模加运算,每个分组都被处理并更新缓冲区的内容。这个过程涉及四个主要的轮函数和一系列的非线性函数。
输出:处理完所有分组后,缓冲区中的内容就是最终的哈希值。这个哈希值是一个128位的数,通常表示为32个十六进制数。
MD5的使用
MD5是一种散列函数,它将输入数据(如密码)转换为固定长度(通常是128位)的散列值。这个过程是不可逆的,即不能从散列值恢复出原始输入。下面代码使用MD5来验证数据的完整性或比较两个数据是否相同
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class MD5Example {
public static void main(String[] args) {
// 原始字符串
String originalString = "这是一个用于MD5加密的示例字符串";
// 生成MD5散列值
String md5Hash = generateMD5(originalString);
System.out.println("原始字符串的MD5散列值: " + md5Hash);
// 验证散列值
boolean isMatch = verifyMD5(originalString, md5Hash);
System.out.println("散列值验证结果: " + isMatch);
// 修改原始字符串并尝试验证
String modifiedString = originalString + "(已修改)";
boolean modifiedMatch = verifyMD5(modifiedString, md5Hash);
System.out.println("修改后字符串的散列值验证结果: " + modifiedMatch);
}
/**
* 生成字符串的MD5散列值
*
* @param input 待加密的字符串
* @return 字符串的MD5散列值
*/
public static String generateMD5(String input) {
try {
// 创建一个MD5消息摘要实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 将输入字符串转换为字节数组,并计算其散列值
byte[] hashBytes = md.digest(input.getBytes(StandardCharsets.UTF_8));
// 将字节数组转换为十六进制字符串
StringBuilder sb = new StringBuilder();
for (byte b : hashBytes) {
sb.append(String.format("%02x", b));
}
return sb.toString();
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5算法不可用", e);
}
}
/**
* 验证给定字符串的MD5散列值是否与期望的散列值匹配
*
* @param input 待验证的字符串
* @param expectedHash 期望的MD5散列值
* @return 如果匹配则返回true,否则返回false
*/
public static boolean verifyMD5(String input, String expectedHash) {
// 生成输入字符串的MD5散列值
String actualHash = generateMD5(input);
// 比较生成的散列值与期望的散列值是否相同
return actualHash.equalsIgnoreCase(expectedHash);
}
}
先定义了一个原始字符串,并使用 generateMD5 方法生成其MD5散列值。然后使用 verifyMD5 方法来验证原始字符串的散列值是否与生成的散列值匹配。最后修改原始字符串并尝试使用相同的散列值进行验证,展示MD5散列值对于数据的敏感性。
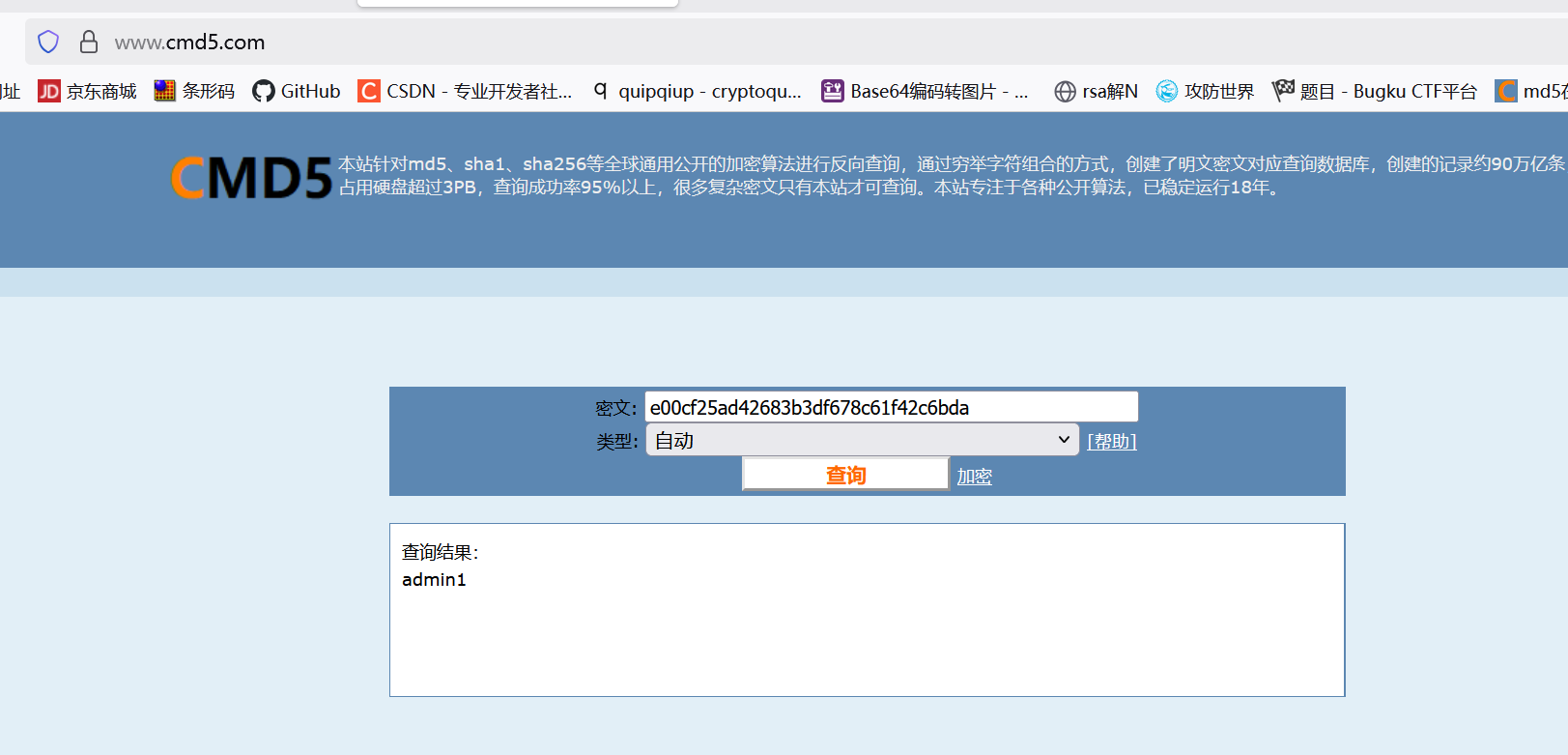
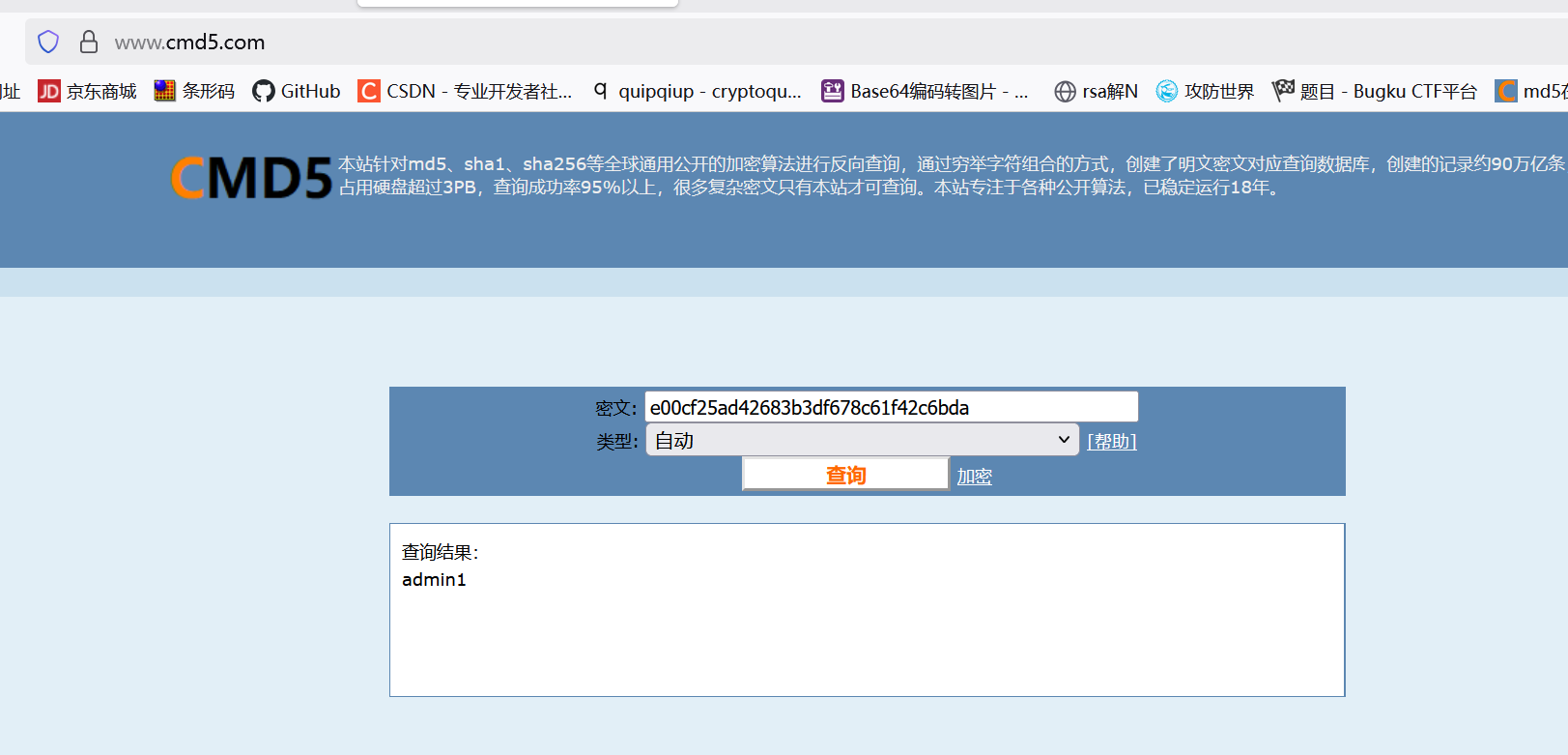
- 例题(BUUCTF-MD5):
题目:e00cf25ad42683b3df678c61f42c6bda
目前只找到在线工具来解密md5
- 例题(BUUCTF-丢失的MD5)
题目:
import hashlib
for i in range(32,127):
for j in range(32,127):
for k in range(32,127):
m=hashlib.md5()
m.update('TASC'+chr(i)+'O3RJMV'+chr(j)+'WDJKX'+chr(k)+'ZM')
des=m.hexdigest()
if 'e9032' in des and 'da' in des and '911513' in des:
print des
这题需要修复代码得到正确的运行结果的题目。
发现 "print des"格式不对,应该改为"print (des)";
又因为代码遵循MD5算法,也就是说在哈希之前必须对Unicode对象进行编码
具体做法就是在"update"函数之中所有的所有参数进行可选参数编码,默认编码为'utf-8'、
import hashlib
for i in range(32,127):
for j in range(32,127):
for k in range(32,127):
m=hashlib.md5()
m.update('TASC'.encode('utf-8')+chr(i).encode('utf-8')+'O3RJMV'.encode('utf-8')+chr(j).encode('utf-8')+'WDJKX'.encode('utf-8')+chr(k).encode('utf-8')+'ZM'.encode('utf-8'))
des=m.hexdigest()
if 'e9032' in des and 'da' in des and '911513' in des:
print (des)
得到![[丢失的MD5flag.png]]