

python实现一些常见编码

Zz1f
URL编码
URL编码方式
URL 的编码方式比较简单,即使用字符 % 后跟两个十六进制数字(0123456789ABCDEF 或 0123456789abcdef)表示字符码值的单个字节值。比如:
https://www.baidu.com/s?wd=春节
因为上面的 URL 参数部分存在 ASCII 无法表示的汉字"春节",因此需要对上面 URL 参数部分进行编码,编码后的 URL 是:
https://www.baidu.com/s?wd=%E6%98%A5%E8%8A%82
其中 0xE698A5 是汉字"春"的 UTF8 码值,0xE88A82 是汉字"节"的 UTF8 码值。
URL特殊字符![[URL特殊字符.png]]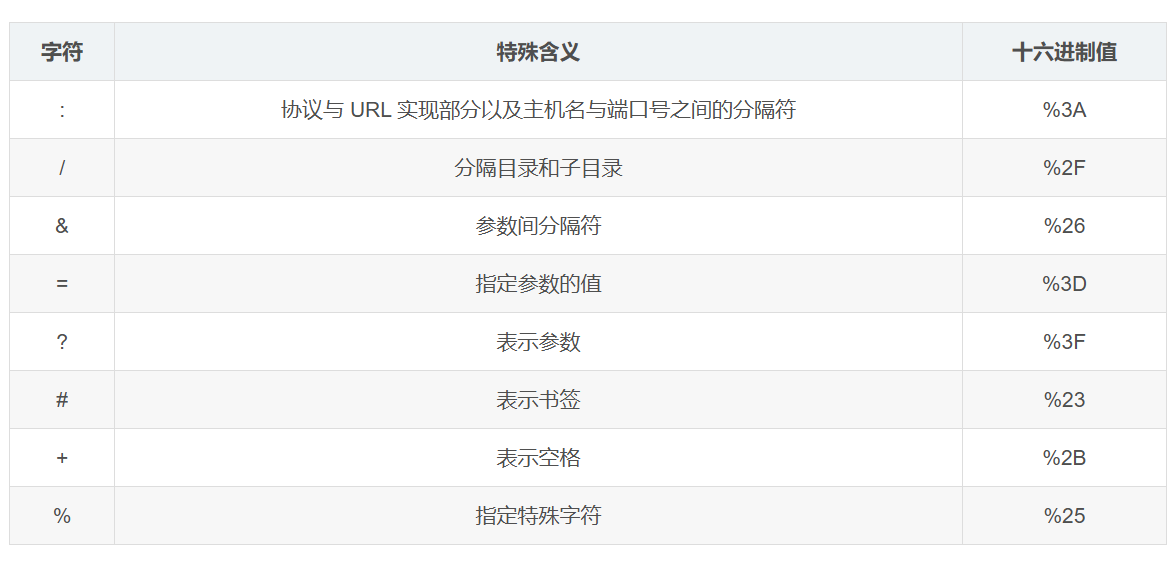
python实现解码编码:
Python 的标准库urllib.parse模块中提供了用来编码和解码的方法,分别是 urlencode() 与 unquote() 方法
![[urlpython.png]]
1) 编码urlencode()
下面以百度搜索为例进行讲解。首先打开百度首页,在搜索框中输入“爬虫”,然后点击“百度一下”。当搜索结果显示后,此时地址栏的 URL 信息,如下所示:
https://www.baidu.com/s?wd=爬虫&rsv_spt=1&rsv_iqid=0xa3ca348c0001a2ab&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=ib&rsv_sug3=8&rsv_sug1=7&rsv_sug7=101
可以看出 URL 中有很多的查询字符串,而第一个查询字符串就是“wd=爬虫”,其中 wd 表示查询字符串的键,而“爬虫”则代表您输入的值。
在网页地址栏中删除多余的查询字符串,最后显示的 URL 如下所示:
https://www.baidu.com/s?wd=爬虫
使用搜索修改后的 URL 进行搜索,依然会得到相同页面。因此可知“wd”参数是百度搜索的关键查询参数。下面编写爬虫程序对 “wd=爬虫”进行编码,如下所示:
#导入parse模块
from urllib import parse
#构建查询字符串字典
query_string = {
'wd' : '爬虫'
}
#调用parse模块的urlencode()进行编码
result = parse.urlencode(query_string)
#使用format函数格式化字符串,拼接url地址
url = 'http://www.baidu.com/s?{}'.format(result)
print(url)
输出结果:
wd=%E7%88%AC%E8%99%AB
http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
编码后的 URL 地址依然可以通过地网页址栏实现搜索功能。
除了使用 urlencode() 方法之外,也可以使用 quote(string) 方法实现编码,代码如下:
from urllib import parse
#注意url的书写格式,和 urlencode存在不同
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入要搜索的内容:')
#quote()只能对字符串进行编码
query_string = parse.quote(word)
print(url.format(query_string))
输出结果如下:
输入:请输入要搜索的内容:编程帮www.biancheng.net
输出:http://www.baidu.com/s?wd=%E7%BC%96%E7%A8%8B%E5%B8%AEwww.biancheng.net
注意:quote() 只能对字符串编码,而 urlencode() 可以直接对查询字符串字典进行编码。因此在定义 URL 时,需要注意两者之间的差异。方法如下:
urllib.parse
urllib.parse.urlencode({'key':'value'}) #字典
urllib.parse.quote(string) #字符串
2)解码unquote(string)
解码是对编码后的 URL 进行还原的一种操作,示例代码如下:
from urllib import parse
string = '%E7%88%AC%E8%99%AB'
result = parse.unquote(string)
print(result)
输出结果:
爬虫
3) URL地址拼接方式
三种拼接 URL 地址的方法。除了使用 format() 函数外,还可以使用字符串相加,以及字符串占位符,总结如下:
纯文本复制
# 1、字符串相加
baseurl = 'http://www.baidu.com/s?'
params='wd=%E7%88%AC%E8%99%AB'
url = baseurl + params
# 2、字符串格式化(占位符)
params='wd=%E7%88%AC%E8%99%AB'
url = 'http://www.baidu.com/s?%s'% params
# 3、format()方法
url = 'http://www.baidu.com/s?{}'
params='wd=%E7%88%AC%E8%99%AB'
url = url.format(params)
例题
题目给了这样一串URL编码:
%66%6c%61%67%7b%61%6e%64%20%31%3d%31%7d
使用脚本来解
解出flag:flag{and 1=1}
凯撒密码
基本原理是通过将明文中的字符按照一定顺序移动固定的位置来生成密文。比如,我们规定把每个字母向后移动 3 位,那么字母 A 就会变成 D,B 变成 E,C 变成 F 等,若移动到了字母表末尾就再从开头循环,像 X 变成 A,Y 变成 B,Z 变成 C。
假设我们有明文 “APPLE”,按照上述后移 3 位的规则加密,A 变成 D,P 变成 S,L 变成 O,E 变成 H,密文就成了 “DSSOH”。解密的时候,就把密文的字母再往前移 3 位,就能还原出明文。
根据这个我们可以写一个python的解密脚本:
# 导入 string 模块,该模块提供了一系列有用的字符串常量
import string
# 导入 time 模块,用于计算程序的运行时间
import time
# 定义一个包含所有可能字符的字符串
# string.ascii_lowercase 包含所有小写字母
# string.ascii_uppercase 包含所有大写字母
# string.digits 包含所有数字
# string.punctuation 包含所有标点符号
# 最后加上一个空格,涵盖了可能出现在文本中的常见字符
letters = string.ascii_lowercase + string.ascii_uppercase + string.digits + string.punctuation + ' '
# 定义一个名为 caesar 的函数,用于对给定的密文进行凯撒密码破解
def caesar(ciphertext):
# 遍历所有可能的密钥,密钥的范围是从 0 到 letters 字符串的长度 - 1
for key in range(len(letters)):
# 初始化一个空字符串,用于存储解密后的消息
message = ""
# 遍历密文中的每个字符
for symbol in ciphertext:
# 检查当前字符是否在 letters 字符串中
if symbol in letters:
# 找到当前字符在 letters 字符串中的索引
sindex = letters.find(symbol)
# 计算解密后的字符在 letters 字符串中的索引
# 通过减去密钥并对 letters 字符串的长度取模,实现循环移位
mindex = (sindex - key) % len(letters)
# 将解密后的字符添加到 message 字符串中
message += letters[mindex]
else:
# 如果当前字符不在 letters 字符串中,直接将其添加到 message 字符串中
message += symbol
# 打印使用当前密钥破解得到的字符串
print(f"使用密钥{key}破解得到的字符串是{message}")
# 定义需要破解的密文
ciphertext = "OUJPEQJ4NIJIPXXMIMJ7G"
# 记录程序开始运行的时间
start_time = time.time()
# 调用 caesar 函数对密文进行破解
caesar(ciphertext)
# 打印程序总共运行的时间,即当前时间减去开始时间
print(f"共用时:{time.time() - start_time}秒")
例题
题目给的编码:
synt{5pq1004q-86n5-46q8-o720-oro5on0417r1}
这看着很像flag形式,但是却又不是,想到是每个字符有偏移,因此用脚本,发现我的其他字符也变了,很不好找,因此我修改了一下脚本
![[其他字符修改.png]]
import string
import time
# 定义一个只包含字母和数字的字符串
letters_and_digits = string.ascii_lowercase + string.ascii_uppercase + string.digits
# 定义一个名为 caesar 的函数,用于对给定的密文进行凯撒密码破解
def caesar(ciphertext):
# 遍历所有可能的密钥,密钥的范围是从 0 到 letters_and_digits 字符串的长度 - 1
for key in range(len(letters_and_digits)):
# 初始化一个空字符串,用于存储解密后的消息
message = ""
# 遍历密文中的每个字符
for symbol in ciphertext:
# 检查当前字符是否在 letters_and_digits 字符串中
if symbol in letters_and_digits:
# 找到当前字符在 letters_and_digits 字符串中的索引
sindex = letters_and_digits.find(symbol)
# 计算解密后的字符在 letters_and_digits 字符串中的索引
# 通过减去密钥并对 letters_and_digits 字符串的长度取模,实现循环移位
mindex = (sindex - key) % len(letters_and_digits)
# 将解密后的字符添加到 message 字符串中
message += letters_and_digits[mindex]
else:
# 如果当前字符不在 letters_and_digits 字符串中,直接将其添加到 message 字符串中
message += symbol
# 打印使用当前密钥破解得到的字符串
print(f"使用密钥{key}破解得到的字符串是{message}")
# 定义需要破解的密文
ciphertext = "synt{5pq1004q-86n5-46q8-o720-oro5on0417r1}"
# 记录程序开始运行的时间
start_time = time.time()
# 调用 caesar 函数对密文进行破解
caesar(ciphertext)
# 打印程序总共运行的时间,即当前时间减去开始时间
print(f"共用时:{time.time() - start_time}秒")
这样就使得其他字符不修改的偏移
![[其他字符不修改.png]]
得到flag:flag{ScdONNRd-VTaS-RTdV-bUPN-bebSbaNROUeO}
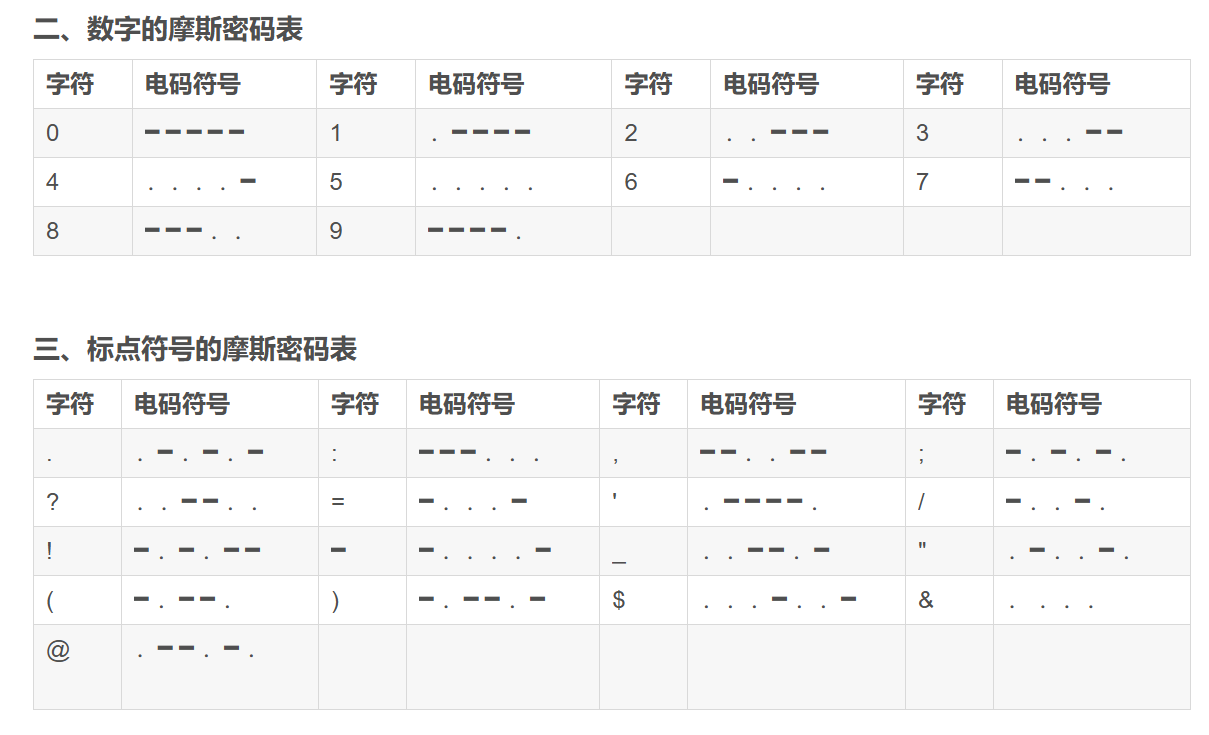
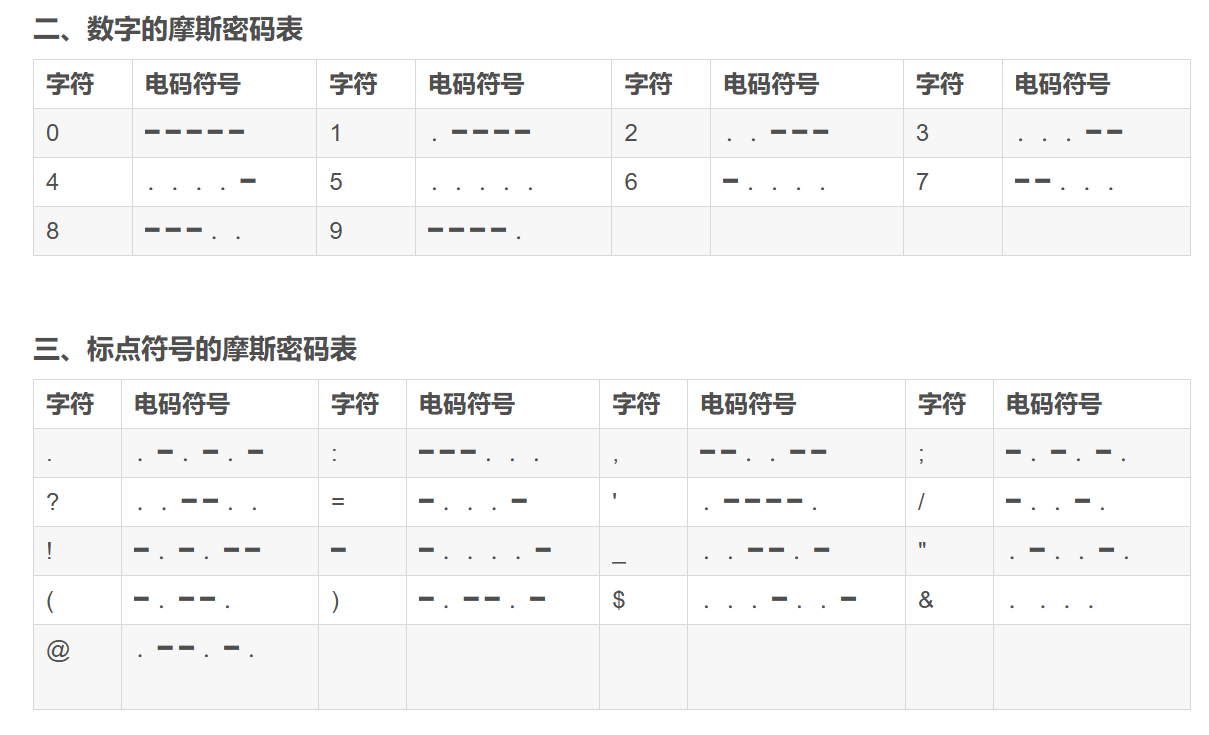
摩丝密码
摩丝密码表:
![[26个字母的摩斯密码表.png]]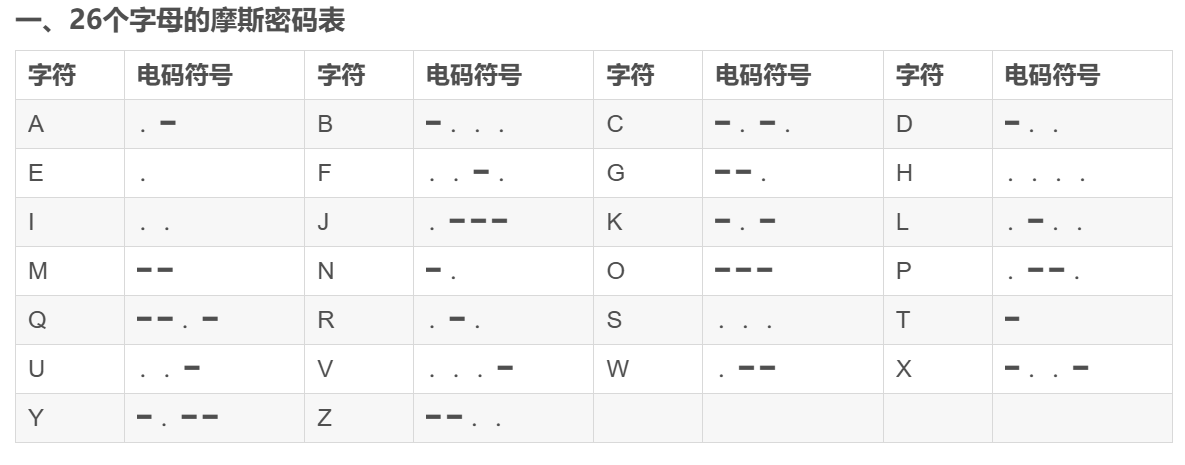
python实现代码:
# 实现摩斯密码翻译器的 Python 程序
'''
VARIABLE KEY
'cipher' -> '存储英文字符串的摩斯翻译形式'
'decipher' -> '存储摩斯字符串的英文翻译形式'
'citext' -> '存储单个字符的摩斯密码'
'i' -> '计算摩斯字符之间的空格'
'message' -> '存储要编码或解码的字符串
'''
# 表示摩斯密码图的字典
MORSE_CODE_DICT = { 'A':'.-', 'B':'-...',
'C':'-.-.', 'D':'-..', 'E':'.',
'F':'..-.', 'G':'--.', 'H':'....',
'I':'..', 'J':'.---', 'K':'-.-',
'L':'.-..', 'M':'--', 'N':'-.',
'O':'---', 'P':'.--.', 'Q':'--.-',
'R':'.-.', 'S':'...', 'T':'-',
'U':'..-', 'V':'...-', 'W':'.--',
'X':'-..-', 'Y':'-.--', 'Z':'--..',
'1':'.----', '2':'..---', '3':'...--',
'4':'....-', '5':'.....', '6':'-....',
'7':'--...', '8':'---..', '9':'----.',
'0':'-----', ', ':'--..--', '.':'.-.-.-',
'?':'..--..', '/':'-..-.', '-':'-....-',
'(':'-.--.', ')':'-.--.-'}
# 根据摩斯密码图对字符串进行加密的函数
def encrypt(message):
cipher = ''
for letter in message:
if letter != ' ':
# 查字典并添加对应的摩斯密码
# 用空格分隔不同字符的摩斯密码
cipher += MORSE_CODE_DICT[letter] + ' '
else:
# 1个空格表示不同的字符
# 2表示不同的词
cipher += ' '
return cipher
# 将字符串从摩斯解密为英文的函数
def decrypt(message):
# 在末尾添加额外空间以访问最后一个摩斯密码
message += ' '
decipher = ''
citext = ''
for letter in message:
# 检查空间
if (letter != ' '):
# 计数器来跟踪空间
i = 0
# 在空格的情况下
citext += letter
# 在空间的情况下
else:
# 如果 i = 1 表示一个新字符
i += 1
# 如果 i = 2 表示一个新词
if i == 2 :
# 添加空格来分隔单词
decipher += ' '
else:
# 使用它们的值访问密钥(加密的反向)
decipher += list(MORSE_CODE_DICT.keys())[list(MORSE_CODE_DICT
.values()).index(citext)]
citext = ''
return decipher
# 硬编码驱动函数来运行程序
def main():
message = "1"
result = encrypt(message.upper())
print (result)
message = ".. .-.. --- ...- . -.-- --- ..-"
result = decrypt(message)
print (result)
# 执行主函数
if __name__ == '__main__':
main()