

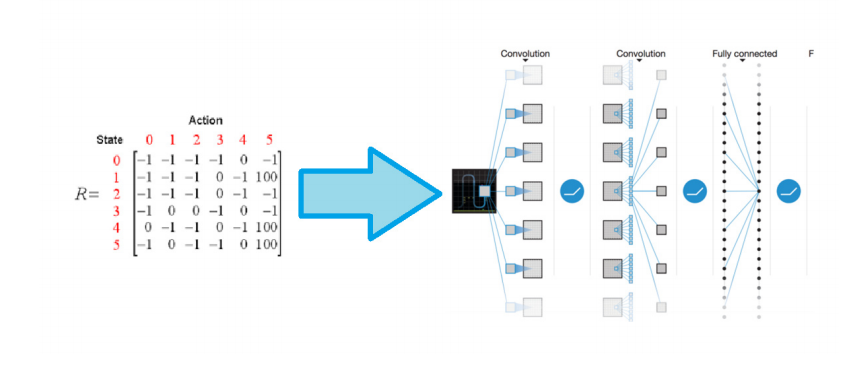
强化学习

没有名字
强化学习的基本框架是代理(Agent)根据环境选择行动,然后通过这个行动改变环境。根据环境的变化,代理获得某种报酬。强化学习的目的是决定代理的行动方针,以获得更好的报酬。需要注意的是,报酬并不是确定的,只是“预期报酬”。
书中对于强化学习的解释举例了超级马里奥兄弟这款游戏:比如我们有一个Agent就是马里奥本人,那么马里奥可以采取的行动就是前进,后退和起跳,对于不同的动作,环境会给我们不同的反馈,比如在一个有怪物的地方起跳,马里奥就能躲过这个怪物,如果在这个怪物的地方选择前进,那么马里奥就会损失一条生命,得到一个负反馈等,通过不断的与环境的交互,模型就会学会在不同的情况下采取合适的动作从而得到奖励,也就是说模型就能够学会一种模式,这种模式能够知道在一个环境中应该采取怎样的行动。
在强化学习的算法中有两个部分需要学习,第一部分是环境中每一种动作的得分,比如在马里奥的例子里,我们需要知道在怪物来到之前我们起跳这个动作的得分。第二个部分就是策略,或者说是在某种特定的环境下,我们应该采取什么样的动作来最大化得分。这其实是最像AI的一部分,因为这个部分包含着基于回报进行的决策,非常的像人类,因为人类做出的动作都是基于一些目的的。
Q-learning是强化学习中最经典的算法之一,核心是通过 “试错” 让代理(Agent)学习在不同状态下选择最优动作,最终实现目标。
可以举一个例子,假设一间房屋有5个房间,某些房间之间相连,我们希望可以走出这个房间。
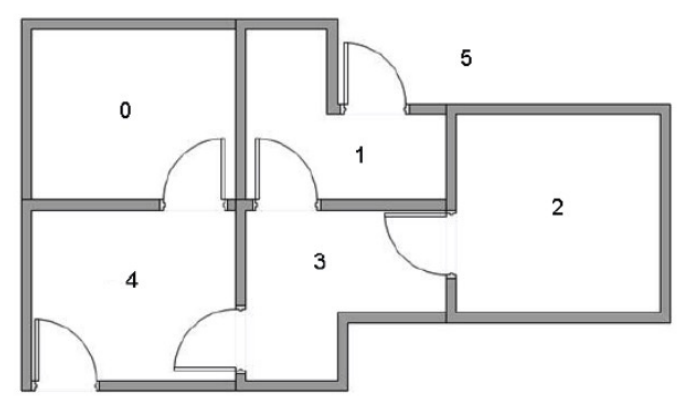
那么我们可以将其简化成一些节点和图的形式,每个房间作为一个节点,两个房间有门相连,就在两个节点之间连接成一条线,如图:
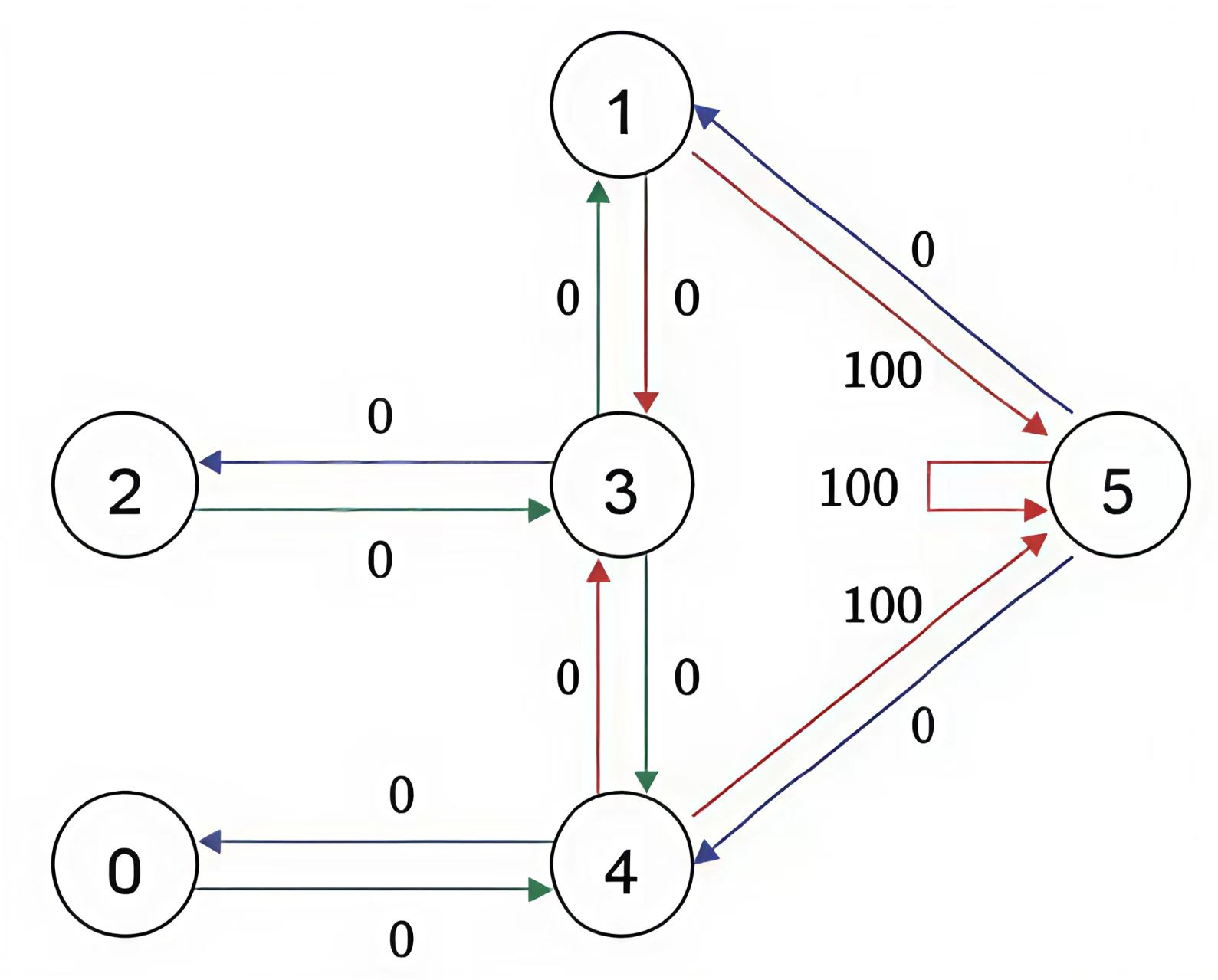
在模拟全过程之前先将Agent放置在任何一个房间,为了能够让Agent知道5号节点是目标房间,我们需要设置一些奖励,对于每一条边,我们都关联一个奖励值,如下图设直接连到目标房间的边的奖励值为100,其他边可以设置为0。需要注意的是,为了能让Agent选择一直待在5号房间,我们需要把5号房间指向自己的箭头的奖励值也设置为100,这样当Agent到达5号房间后就会一直呆在那里,这也称为吸收目标
Q-learning 的核心是 Q 值(Q-value),它的定义是:
Q (s, a) = 在状态 s 下,选择动作 a 能获得的 “长期累积奖励的预期值”。
简单说,Q (s,a) 越高,说明在状态 s 下做动作 a 越 “划算”。Q-learning 的目标就是学习出一张 “Q 表”(记录所有状态 s 和动作 a 对应的 Q 值),有了这张表,智能体就能在任何状态下直接选择 Q 值最高的动作,实现最优决策。
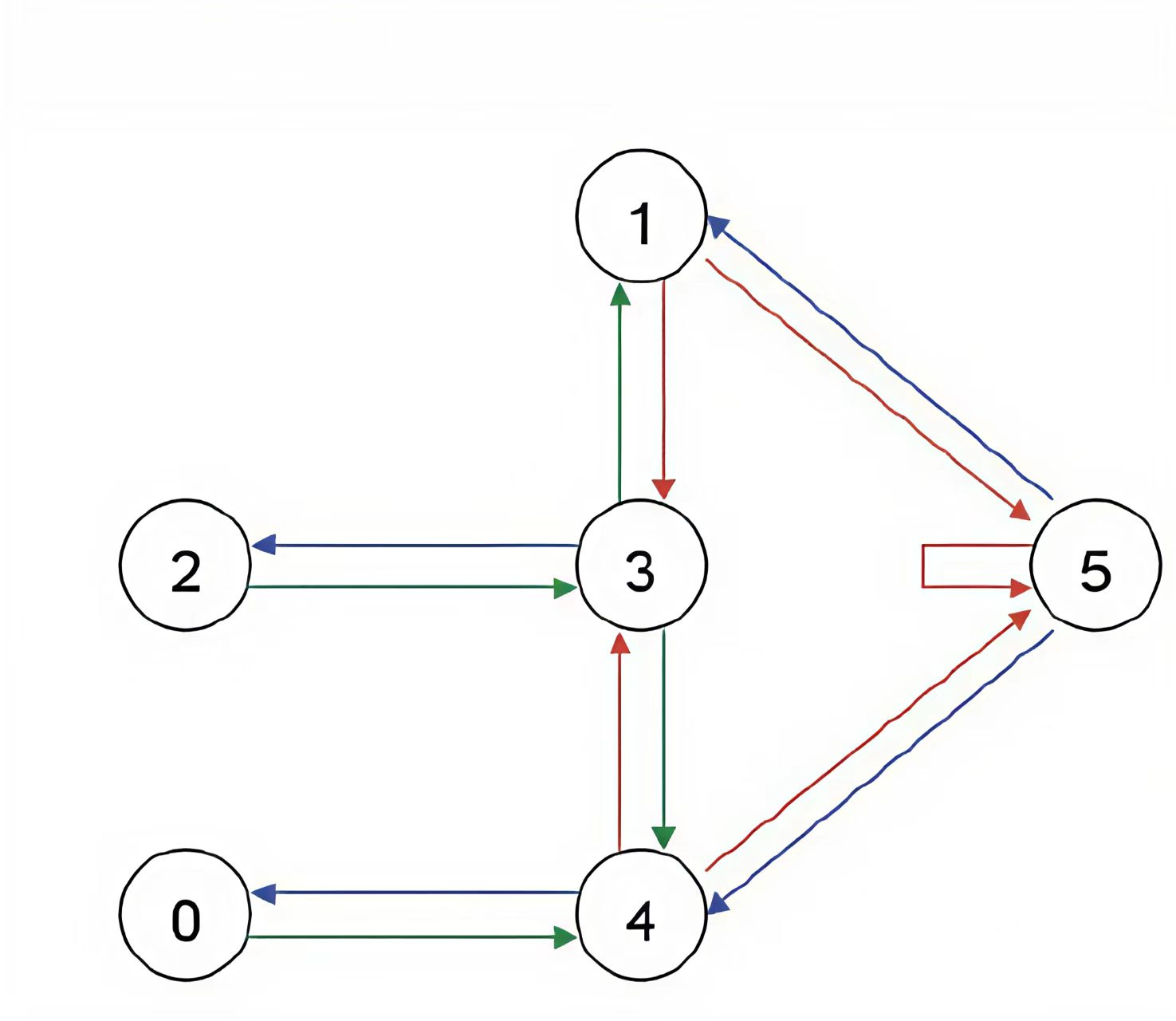
我们将每一个房间都称为一个状态,而Agent从一个房间走到另一个房间称为一个动作,对应上面的图就是每个节点是一个状态,每个箭头都是一种行动。假如Agent处在状态4,从状态4来看可以选择走到状态0或者状态3或者状态5,如果走到了状态3,也可以选择走到状态2或者状态1或者状态4。我们可以根据状态和动作得到的奖励来建立一个奖励表,用-1表示相应节点之间没有边相连,而没有到达终点的边的奖励记为0

类似的,我们可以让Agent通过和环境的交互来不断学习环境中的知识,让智能体根据每个状态来估计每 种行动可能得到的收益,这个矩阵被称为Q表,每一行表示状态,每一列表示不同的动作,对于状态未 知的情景,我们可以随机让Agent从任何的位置出发,然后去探索新的环境来尽可能的得到所有的状态。刚开始Agent对于环境一无所知,所以数值全部初始化为0,如下
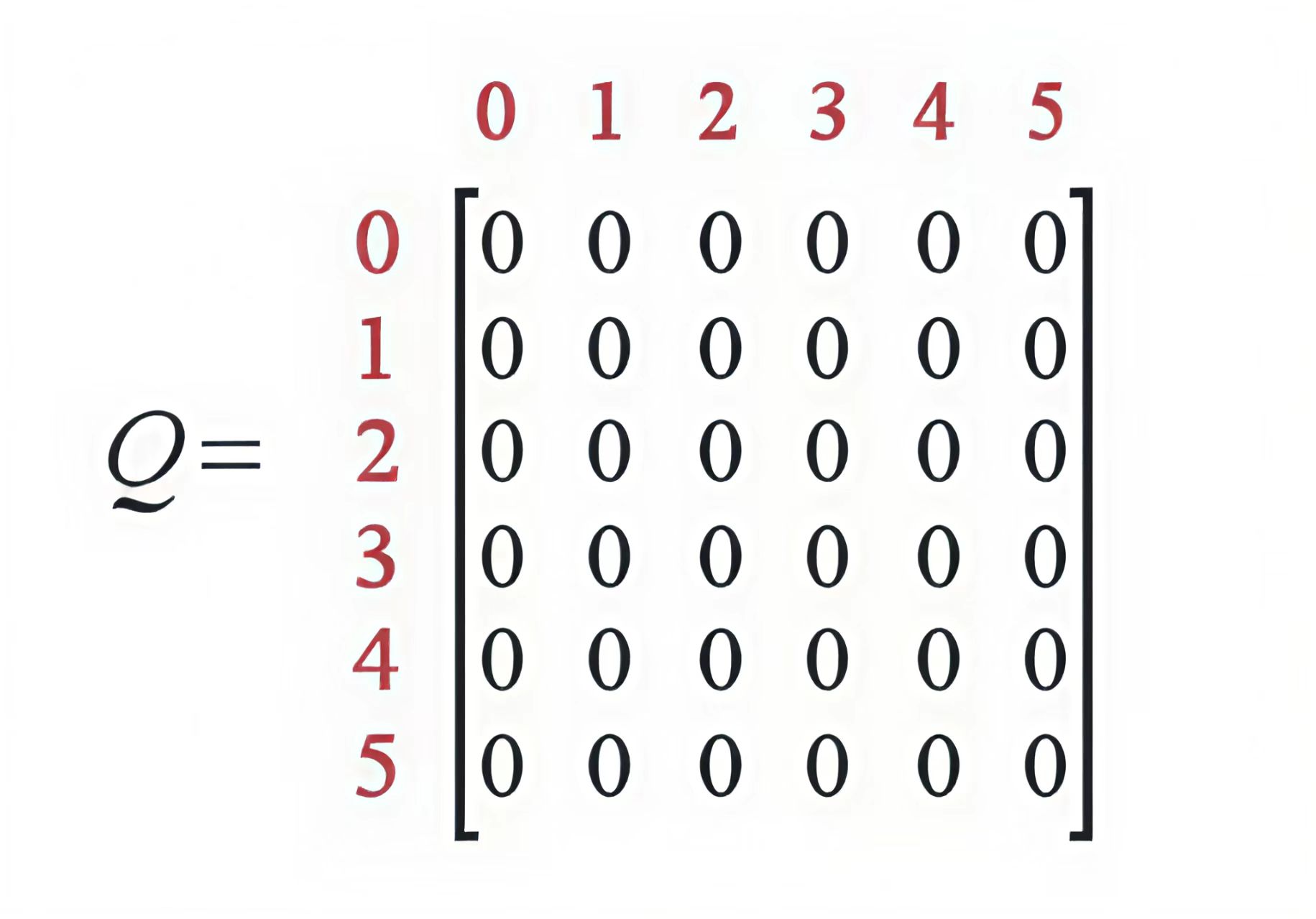
Agent通过不断地学习来更新Q表中的结果,最后依据Q表中的值来做决策。
Q-learning算法的转移公式如下:

解释一下就是Agent通过经验进行自主学习,不断从一个状态转移到另外一个状态进行探索,并在这个过程中不断更新Q表,直到到达目标位置, Q 表就像Agent的大脑,更新越多就越强。我们称Agent的每一次探索为episode,每个episode都表示Agent从任意初始状态到达目标状态,当Agent到达一个目标状态,那么当前的episode结束,进入下一个episode。
整个流程就是:
第一步先给定参数 γ 和奖励矩阵R,
第二步令Q=0,
第三步为for each episode:
3.1随机选择一个初始状态s
3.2若最终未达到目标状态,执行以下几步:
3.2.1在当前状态s的所有可能行动中选取一个行为a
3.2.2利用选定的行为a,得到下一个状态~s
3.2.3按照前面的转移公式计算Q(s,a)
3.2.4令 s=~s
假设演示:选择 γ=0.8,初始状态=1,Q初始化为零矩阵

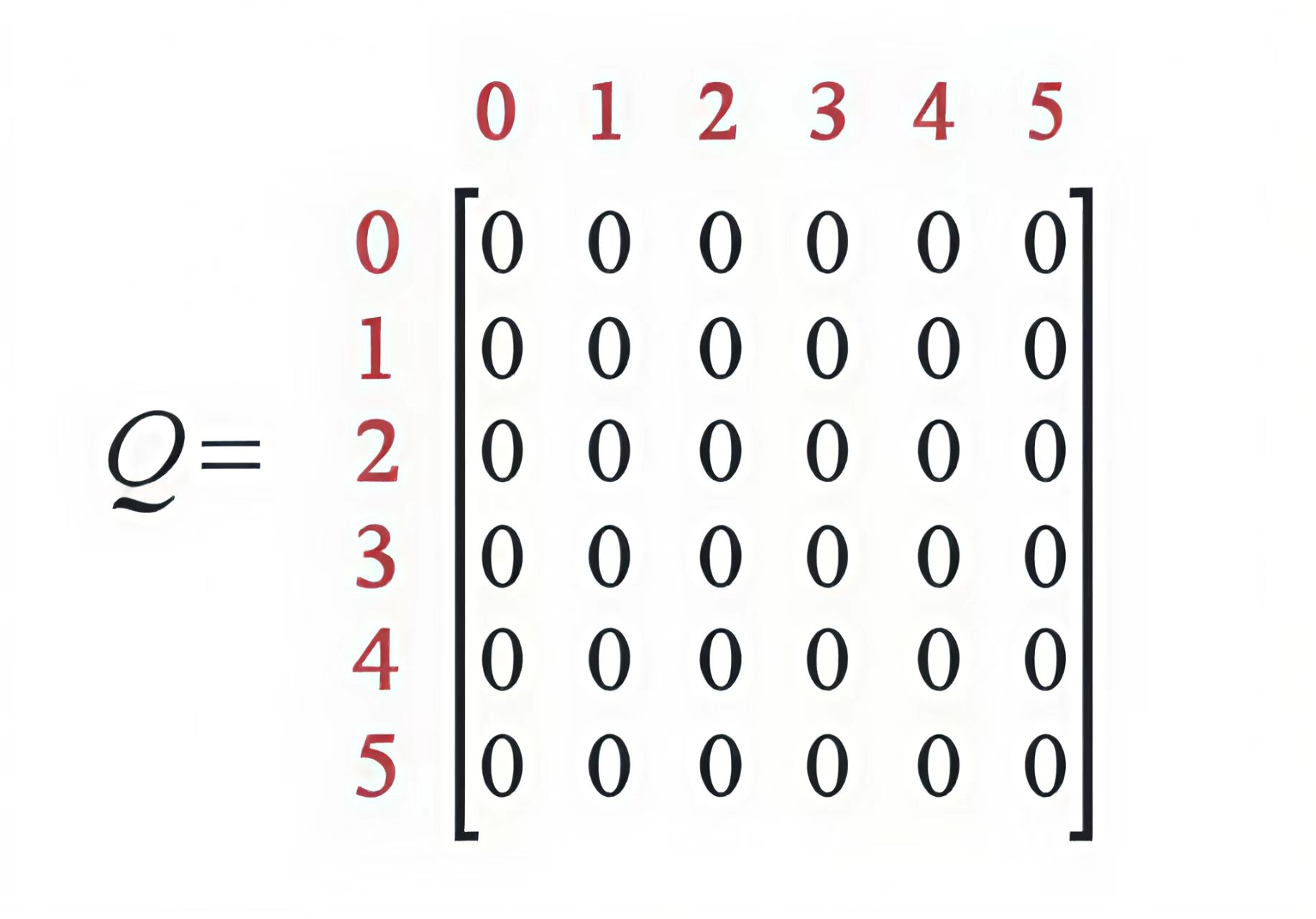
因为是状态1,所以我们观察R矩阵的第二行,负数表示非法行为,所以下一个状态只有两种可能,走到状态3或者状态5,随机地,我们可以选择走到状态5。
当我们走到状态5之后,会发生什么事情呢?观察R矩阵的第6行可以发现,其对应于三个可能采取的动作:转至状态1,4或者5,根据上面的转移公式,我们有
[Q(1,5)=R(1,5)+0.8max{ Q(5,1),Q(5,4),Q(5,5)} =100+0.8max{ 0,0,0} =100]
所以现在Q矩阵进行了更新,变为了

现在我们的状态由1变成了5,因为5是最终的目标状态,所以一次episode便完成了,进入下一个 episode。在下一个episode中又随机选择一个初始状态开始,不断更新Q矩阵,在经过了很多个episode之后, 矩阵Q接近收敛,那么我们的Agent就学会了从任意状态转移到目标状态的最优路径。
Deep Q-Networks
我们知道对于q-learning,我们需要使用一个Q表来存储我们的状态和动作,每次我们使用Agent不断探索环境来更新Q表,最后我们能够根据Q表中的状态和动作来选择最优的策略。但是使用这种方式有一个很大的局限性,如果在现实生活中,情况就会变得非常的复杂,我们可能有成干上万个state,甚至有可能是无穷无尽的state,对于这种情况,我们不可能将所有的state都用Q表来存储,那么我们该如何解决这个问题呢?
一个非常简单的办法就是使用深度学习来解决这个问题,所以出现了一种新的网络,叫做Deep Q-Networks,将Q-learning和神经网络结合在了一起,对于每一个state,我们都可以使用神经网络来计算对应动作的值,就不在需要建立一张表格,而且网络更新比表格更新更有效率,获取结果也更加高效。
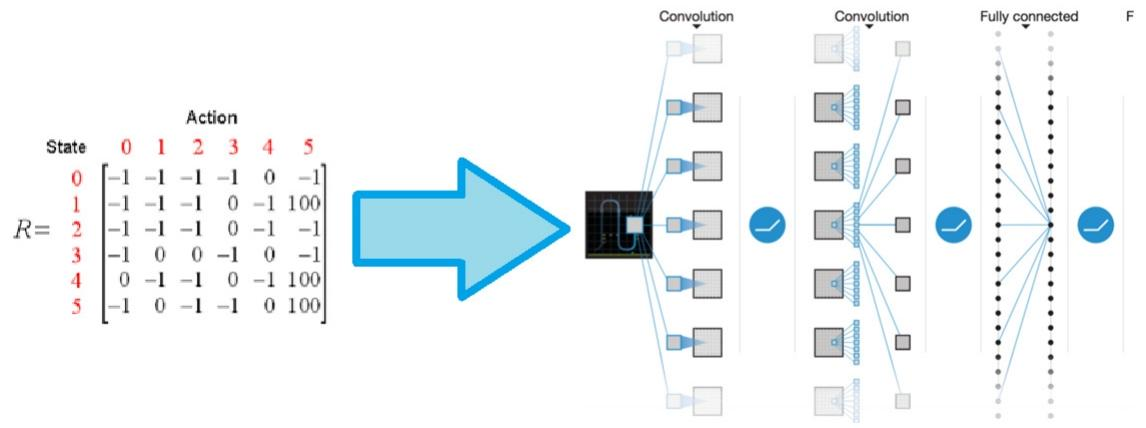
DQN 的神经网络结构通常为卷积神经网络(CNN)+ 全连接层
传统 Q-Learning 通过Q 表存储每个状态(s)和动作(a)的价值Q(s,a),但当状态是高维连续空间(如游戏画面的像素值)时,Q 表会因 “维度灾难” 失效。DQN 的核心突破是:用神经网络近似 Q 值函数,即通过神经网络直接输出任意状态s下所有动作的 Q 值Q(s,a;θ),其中θ是网络参数。
强化学习的样本(状态、动作、奖励、下一状态)具有时间相关性,直接用于训练会导致神经网络参数更新不稳定。因此Agent与环境交互时,将每次的经验(s, a, r, s')存储到回放缓冲区。训练时,从缓冲区中随机采样批量样本(打破时间相关性),用于更新网络参数。若用同一网络同时估计当前 Q 值和目标 Q 值,会导致 “目标移动问题”(参数更新时目标值也在变化,难以收敛)。此时需要引入两个结构相同但参数不同的网络(评估网络和目标网络),评估网络实时更新参数,用于输出当前状态的 Q 值(Q(s,a;θ),目标网络定期复制评估网络的参数(如每 1000 步更新一次),用于计算目标 Q 值(Q'(s',a';θ−)),其中θ−是目标网络参数。
DQN 的训练通过最小化 “预测 Q 值” 与 “目标 Q 值” 的差异实现,损失函数为均方误差(MSE):
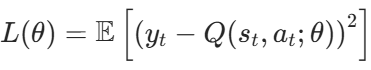
y_t是目标 Q 值,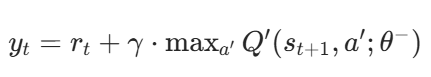
r_t:当前动作的即时奖励
γ:折扣因子(对未来奖励的衰减)
max_a'Q'(s_t+1,a';θ-):目标网络预测的下一状态最优 Q 值